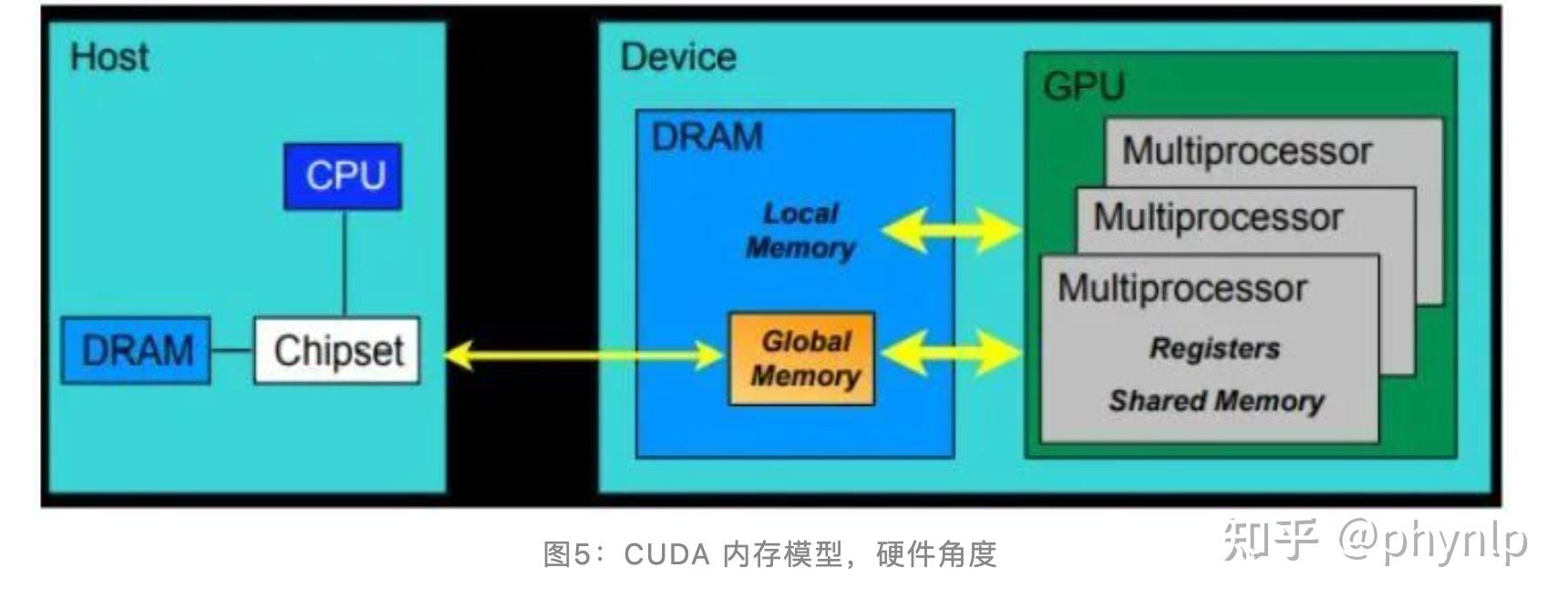
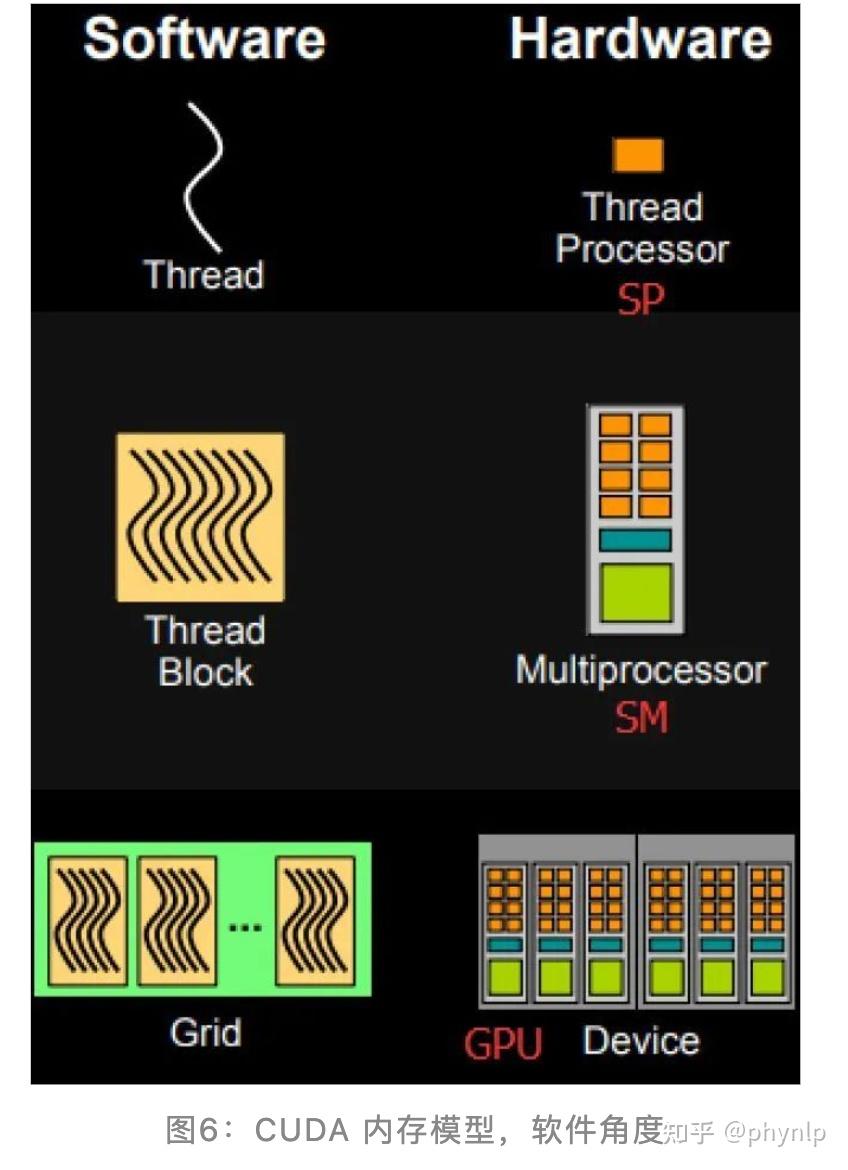
CUDA的内存模型:
SP(线程处理器,流式处理器):CUDA内存模型的基本单位,包含Registers(寄存器)和local memory(局部内存)。不同的线程之间彼此独立,寄存器和局部内存只能被线程自己访问。
SM(多核处理器):由多个线程处理器和共享内存组成。多线程处理器是并行的,互不影响的。共享内存可以被多核处理器(线程块)中的所有线程访问。
GPU:有多个多核处理器和一块全局内存构成。一个GPU的所有SM共有一块全局内存,不同线程块(SM)的线程都可以使用。不同的GPU(不同的grid)则有各自的global memory。 Streaming Process Model
统一的流处理器取代GPU中原有的不同着色单元的设计,释放了GPU的计算能力。
流式编程技术简化了软件和硬件的并行处理流程。
Stream processing is a programming technique which simplifies hardware and software parallel processing.
In the stream programming model, all data is represented as a stream. 流式处理模型,以流式的方式处理句子。Kernel outputs are functions only of their kernel inputs, and within a kernel, computations on one stream element are never dependent on computations on another element.流式运算的核函数,对流式数据中的计算是完全独立的。
A CUDA-enabled GPU can have a scalable array of multithreaded streaming multiprocessors (SMs), which is roughly equivalent to CPU cores. Each SM can have certain number of scalar processors (i.e., streaming processors, SPs) with respect to the specific architecture.
SMs为多线程流式处理器,包含多个流式处理器(SPs,标量处理器) 逻辑体系架构:



 发表于 2022-12-1 16:21:54
发表于 2022-12-1 16:21:54